Test chí-kvadrát s Excelem
Chi-Square test v aplikaci Excel je nejčastěji používaný neparametrický test používaný k porovnání dvou nebo více proměnných pro náhodně vybraná data. Jedná se o typ testu, který se používá ke zjištění vztahu mezi dvěma nebo více proměnnými, používá se ve statistikách, které se také nazývají Chi-Square P-hodnota, v aplikaci Excel nemáme vestavěnou funkci, ale můžeme použít vzorce k provedení testu chí-kvadrát v aplikaci Excel pomocí matematického vzorce pro test chí-kvadrát.
Typy
- Chi-Square test na dobrou shodu
- Chi-Square test nezávislosti dvou proměnných.
# 1 - Chi-Square test na dobrou shodu
Používá se k vnímání blízkosti vzorku, který vyhovuje populaci. Symbol testu Chi-Square je (2). Je to součet všech ( pozorovaný počet - očekávaný počet) 2 / očekávaný počet.
- Kde k-1 stupňů volnosti nebo DF.
- Kde Oi je pozorovaná frekvence, k je kategorie a Ei je očekávaná frekvence.
Poznámka: - Dobrá shoda statistického modelu se týká porozumění tomu, jak dobře se data vzorku hodí k souboru pozorování.
Použití
- Důvěryhodnost dlužníků na základě jejich věkových skupin a osobních půjček
- Vztah mezi výkonem prodejců a absolvovaným školením
- Návratnost jedné akcie a akcií sektoru, jako je farmaceutický nebo bankovní sektor
- Kategorie diváků a dopad televizní kampaně.
# 2 - Chi-Square test nezávislosti dvou proměnných
Používá se ke kontrole, zda jsou proměnné navzájem autonomní nebo ne. S (r-1) (c-1) stupni volnosti
Kde Oi je pozorovaná frekvence, r je počet řádků, c je počet sloupců a Ei je očekávaná frekvence
Poznámka: - Dvě náhodné proměnné se nazývají nezávislé, pokud rozdělení pravděpodobnosti jedné proměnné není ovlivněno druhou.Použití
Test nezávislosti je vhodný pro následující situace:
- Existuje jedna kategorická proměnná.
- Existují dvě kategorické proměnné a budete muset určit vztah mezi nimi.
- Existují křížové tabulky a je třeba najít vztah mezi dvěma kategorickými proměnnými.
- Existují nekvantifikovatelné proměnné (Například odpovědi na otázky typu: vybírají si zaměstnanci v různých věkových skupinách různé typy zdravotních plánů?)
Jak provést test Chi-Square v aplikaci Excel? (s příkladem)
Manažer restaurace chce najít vztah mezi spokojeností zákazníků a platy lidí čekajících na stoly. V tomto nastavíme hypotézu k testování chí-kvadrátu
- Vzala náhodný vzorek 100 zákazníků s dotazem, zda byla služba vynikající, dobrá nebo špatná.
- Poté kategorizuje platy čekajících lidí na nízké, střední a vysoké.
- Předpokládejme, že úroveň významnosti je 0,05. Zde H0 a H1 označují nezávislost a závislost kvality služeb na platech čekajících lidí.
- H 0 - kvalita služeb nezávisí na platech lidí čekajících na stoly.
- H 1 - kvalita služeb závisí na platech lidí čekajících na stole.
- Její zjištění jsou uvedena v následující tabulce:
V tomto máme 9 datových bodů, máme 3 skupiny, z nichž každá dostala jinou zprávu o platu a výsledek je uveden níže.

Nyní budeme počítat součet všech řádků a sloupců. Uděláme to pomocí vzorce, tj. SUMA. Abychom ve sloupci Celkem sčítali vynikající, napsali jsme = SUM (B4: D4) a poté stiskněte klávesu Enter.

To nám dá 26 . U všech řádků a sloupců provedeme totéž.

Pro výpočet stupně svobody (DF) používáme (r-1) (c-1)
DF = (3-1) (3-1) = 2 * 2 = 4
- Existují 3 kategorie služeb a 3 kategorie platu.
- Máme 27 respondentů se středním platem (spodní řádek, střední)
- Máme 51 respondentů s dobrou službou (poslední sloupec, uprostřed)
Nyní musíme vypočítat očekávané frekvence: -
Očekávané frekvence lze vypočítat pomocí vzorce: -
- Pro výpočet pro Výborný použijeme vynásobení součtu Nízkých a součtu Výborných děleno N.
Předpokládejme, že musíme počítat pro 1. řádek a 1. sloupec (= B7 * E4 / B9 ) . To dá očekávanému počtu zákazníků, kteří zvolili Vynikající služby pro platy čekajících lidí, nízký, tj. 8,32 .
- E 11 = - (32 * 26) / 100 = 8,32 , E 12 = 7,02 , E 13 = 10,66
- E 21 = 16,32 , E 22 = 13,77 , E 23 = 20,91
- E 31 = 7,36 , E 32 = 6,21 , E 33 = 9,41
Podobně pro všechny musíme udělat totéž a vzorec je použit v níže uvedeném diagramu.

Získáme tabulku očekávané frekvence, jak je uvedeno níže: -

Poznámka: - Předpokládejme, že úroveň významnosti je 0,05. Zde H0 a H1 označují nezávislost a závislost kvality služeb na platech čekajících lidí.
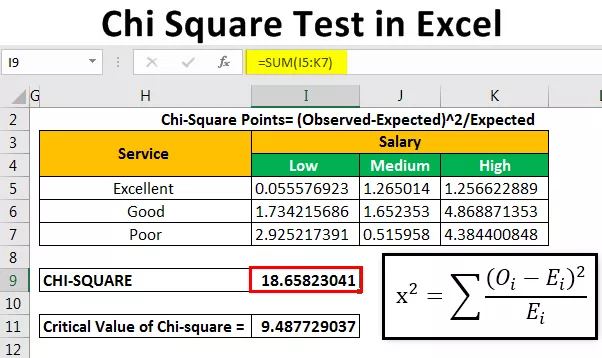
Po výpočtu očekávané frekvence vypočítáme datové body chí-kvadrát pomocí vzorce.
Body Chi-Square = (pozorováno - očekáváno) 2 / očekáváno
Pro výpočet prvního bodu napíšeme = (B4-B14) 2 / B14.

Zkopírujeme a vložíme vzorec do jiných buněk, abychom automaticky vyplnili hodnotu.

Poté vypočítáme hodnotu chi (vypočítaná hodnota) sečtením všech hodnot uvedených nad tabulkou.

Hodnotu Chi jsme dostali jako 18 65823 .

K výpočtu kritické hodnoty použijeme tabulku kritických hodnot chí-kvadrát, můžeme použít vzorec uvedený níže.
Tento vzorec obsahuje 2 parametry CHISQ.INV.RT (pravděpodobnost, stupeň volnosti).
Pravděpodobnost je 0,05 a je to významná hodnota, která nám pomůže určit, zda přijmout nulovou hypotézu (H 0 ) nebo ne.

Kritická hodnota chí-kvadrátu je 9,487729037.

Nyní najdeme hodnotu chí-kvadrátu nebo (P-hodnota) = CHITEST (skutečný_rozsah, očekávaný_rozsah)
Rozsah od = CHITEST (B4: D6, B14: D16) .

Jak jsme viděli, hodnota chi-testu nebo P-hodnoty je = 0,00091723.

Vypočítali jsme všechny hodnoty. Hodnoty chí-kvadrát (vypočítaná hodnota) jsou významné pouze tehdy, když je jejich hodnota stejná nebo větší než kritická hodnota 9,48, tj. Kritická hodnota (tabulková hodnota) musí být vyšší než 18,65, aby se akceptovala nulová hypotéza (H 0 ) .
Ale zde Vypočítaná hodnota > Tabulková hodnota
X 2 (vypočteno)> X 2 (uvedeno v tabulce)
18,65> 9,48
V tomto případě odmítneme nulovou hypotézu (H 0 ) a bude přijata Alternativní (H 1 ) .
- Můžeme také použít P-hodnotu k předpovědi stejné, tj. Pokud P-hodnota <= α (významná hodnota 0,05), bude nulová hypotéza odmítnuta.
- Pokud je hodnota P> α , nezavrhujte nulovou hypotézu .
Zde P-hodnota (0,0009172) < α (0,05), odmítnout H 0 , přijmout H 1
Z výše uvedeného příkladu usuzujeme, že kvalita služby závisí na platech čekajících lidí.
Věci k zapamatování
- Považuje druhou mocninu standardní normály.
- Vyhodnocuje, zda se frekvence pozorované v různých kategoriích významně liší od frekvencí očekávaných při stanovené sadě předpokladů.
- Určuje, jak dobře se předpokládaná distribuce hodí k datům.
- Používá kontingenční tabulky (v průzkumech trhu se tyto tabulky nazývají křížové karty).
- Podporuje měření na nominální úrovni.








